

TL;DR
We are currently collecting approximately two billion new datapoints per month (“medium data” by modern standards) and I've invested significant time in tinkering with storage options for our data. Getting storage infrastructure “right” from day one is impossible. Often there is no one “right” solution - it evolves with evolving requirements. Some lessons I learnt along the way:
Every month we are paying for storing all the data that we have collected since we started. Amount of collected data is cumulative — it always goes up and never goes down. Therefore, optimising for storage costs is one of the priorities. Storage format and compression method really matter. We found that Parquet files compressed with Brotli codec work well in our case, saving more than 30% of space and storage costs, compared to “vanilla” gzip compression.
Optimising for efficient querying and ingestion is another goal for us. Again, Parquet files seem to be the optimal choice, particularly if data has consistent schema (which is not always the case with our data).
We have to watch out for the “Small File Problem”. Data Warehouse platforms are like Goldilocks: they do not like when data files are too big or when they are too small. Finding the right balance is not easy, especially if it involves reshuffling data as a post-process after the initial creation.
Context
In data engineering, it’s those little decisions that can stick around and haunt you. Shuffling large volumes of data can become a major operational burden. That’s why its important to make the right architectural decisions early on.
I’ve been tweaking and turning our web data collection setup across projects, mostly trying to optimise for cost and efficiency. Here are the primary costs that I considered:
Operational Costs: This includes the time and resources spent on running analytical queries. Ultimately, the primary purpose of data storage is to enable analysis, and our goal is to make this process as frictionless as possible. We want to eliminate the need for any complex batch jobs each time an analyst has a new idea or wants to answer a new question.
Storage Costs: data storage costs can become significant, especially as data accumulates over time.
Ingestion Costs: The process of importing data into our systems has its own set of costs, including computational expenses.
Getting the architecture right from day one is usually impossible, as the needs and scale of operations evolve over time. Moreover, once we’ve accumualte substantial amounts of data, making any changes becomes really difficult.
So here is my general pragmatic approach:
Keep things simple: Complexity often leads to technical debt.
Don't reinvent the wheel: Try to rely on proven design patterns and tools that are well supported and widely used.
With the amount of data that we add, storage requires careful planning and consideration. This is what our data stack looks like today: all newly-collected data initially goes into Amazon S3, which is basically a standard for large-scale storage. For analysis, we primarily use Snowflake. Snowflake can potentially be costly if it is not used correctly, but it offers flexibility and some powerful capabilities which are typical of modern data warehouse technologies. Here's a simple diagram of how data flows from our web data collection into S3 and then into our DWH:

Some data (primarily metadata) is ingested live using Snowpipe and some data is ingested on-demand at the time of the analysis.
Data Schema: Tailoring Data Storage for Flexibility and Analysis
One of the fundamental decisions in building a scalable data pipeline is choosing an appropriate schema for data storage. Given the diverse formats returned by different websites—from product-level pricing to variant-level details, and even differing geographical pricing or additional attributes like product tags—making the right decision on how the data is going to be stored is very important.
The primary choices are:
Standardised schema: Simplify by only storing common data elements like pricing and inventory levels, discarding any unique attributes that might be returned by individual sites.
Bespoke schemas: Develop unique schemas for each website or project, based on the specific data outputs.
A hybrid schema: approach that incorporates standard fields but also accommodates unique, site-specific information.
I settled with the last option as this method provides the standardization while retaining the flexibility to capture unique data attributes that might prove valuable later on.
The data is uniformly structured across all projects as follow (demonstrating a single row example):

The first three fields serve as meta-data about a captured datapoint. These fields are very useful for real-time monitoring of our scraping operation. We use them to ensure that we are consistently capturing the same number of products in every run. The “product_data” field acts as a catch-all column, storing actual payload data in a semi-structured format.
Example: Handling Figs data
Consider a product example from Figs. The data features a number of attributes including inventory numbers at the product and at the variant levels:
{
"id": "190758681",
"handle": "gift-card",
"description": "Why We Love This Shopping for someone else but not sure what to give them? Give them the gift of choice with a FIGS Gift Card. Gift cards are delivered by email and contain instructions to redeem them at checkout. Our gift cards have no additional processing fees",
"title": "Digital Gift Card",
"totalInventory": -3346,
"productType": "Gift Card",
"updatedAt": "2023-08-07T17:37:57Z",
"createdAt": "2013-12-09T17:34:01Z",
"onlineStoreUrl": null,
"vendor": "FIGS",
"availableForSale": true,
"variants": {
"edges": [
{
"node": {
"id": "436801941",
"title": "$100.00",
"quantityAvailable": -1654,
"price": {
"amount": "100.0",
"currencyCode": "USD"
}
}
},
{
"node": {
"id": "35396097543",
"title": "$150.00",
"quantityAvailable": -208,
"price": {
"amount": "150.0",
"currencyCode": "USD"
}
}
}
]
},
"priceRange": {
"maxVariantPrice": {
"amount": "150.0",
"currencyCode": "USD"
},
"minVariantPrice": {
"amount": "100.0",
"currencyCode": "USD"
}
}
}If this JSON object is stored as a VARIANT column called “product_data” in a Snowflake table called “products”, it allows us to easily query nested data directly. Here’s how we can access variant-level inventory data:
SELECT
product_data:createdAt::TIMESTAMP,
variant.value:node:quantityAvailable::NUMBER AS variant_quantity_available,
variant.value:node:id::STRING AS id
FROM
products,
LATERAL FLATTEN(input => product_data:variants:edges) AS variantThis method of storing data provides the flexibility needed to adapt our queries based on evolving analytical requirements—reflective of the ELT (Extract, Load, Transform) approach. The benefit of this approach is that we can decide how we want to reshape our data at the time of the analysis, as opposed to when we load the data. In this specific Figs example, when we start data collection, we don’t know if we are going to analyse it at the product level or at the variant level and it is best to leave this decision until we build some history and have better understanding of the data and what we might want to do with it.
We can then define all of our data transformation logic in SQL and leverage computational power of data warehouse platforms. For instance, the trailling median calculation which I explained in my previous posts is very computationally heavy. If we want to perform it on variant-level data, we would need a lot of computing power and this is where modern powerful data warehouse technologies come very handy.
Quick tip: Converting JSON into a database-native semi-structured format (VARIANT in the case of Snowflake and JSON in the case of BigQuery) significantly enhances query performance by eliminating the need for on-the-fly JSON parsing. I find that parsing JSON is one of the most expensive operations and generally we want to make sure that we do it only once during data load, or avoid doing it at all—more on that in the next sections.
Storage Formats for Storing Data in S3
Choosing the right storage format for data in S3 involves balancing several factors. With most of the projects currently being in the "data collection" mode—meaning the data is streamed into S3 but not immediately analysed—optimising for storage costs is one of the priorities. The decision narrows down to choosing between formats like CSV, Parquet, Avro, and ORC, and selecting the most efficient compression codec.
Since we use Pandas for a lot of data processing, we have focused on CSV and Parquet formats, which are well-supported by this library. ORC support was only recently added in Pandas and Avro still requires additional handling via third-party libraries. So let’s look at CSV first. These days, ‘CSV’ is like a dirty word for data engineers. The format's major drawback is its lack of defined schema within the file—it names columns and describes content but doesn’t specify details like data types. These must be inferred or explicitly defined during data processing. Parquet is a more modern format - it’s main advantage is that the data is stored in a columnar format which is optimised for querying. It is worth mentioning that the CSV format has a practical advantage of being universally accessible from many different tools like Excel or Tableau. Maybe one day Tableau will offer support for Parquet files, but I think it ‘ain’t gonna happen’ 😁. Alternatively, if there was a way to connect Tableau to DuckDB and use CustomSQL to connect to Parquet files — that would be ideal.
Comparative Testing
I conducted some tests on a sample of CSV files generated across various projects to determine the most effective compression method:
CSV with xz compression offers the highest compression level. XZ compression is very computationally intensive and lacks native support in most data warehouse platforms.
Parquet with Brotli compression stands out for its efficiency and is supported by Snowflake, making it a strong candidate. Brotli is a relatively new compression method, originally developed by Google. It is mainly used for compressing web content and it performs particularly well with compressing text and JSON data. As of 10 July 2024, Brotli-compressed Parquet files are not supported by DuckDB, but my understanding is that Brotli support is in active development.
CSV with bzip2 compression is slighly less effient than parquet+brotli. It is also supported by Snowflake and it is easy of use. This is the format that we currently use across many of our projects.
Most of the tested compression codecs have some additional settings. For instance, Brotli compression can be “turned to 11” by passing compression_level=11 parameter to pyarrow, making it extremely slow, but slighly more efficient.
Choosing the Right Format for Query and Ingestion
Any data that we store will need to be analysed one day and speed of access can be as importnat if not more important as the storage efficency.
There are principally two different ways we can access data stored in S3: we can ingest it into a database or we can query it directly.
Querying data directly from S3 is a trendy architectural pattern these days. This approach underpins the data lake concept, which is compelling because not only it decouples storage from compute, but it also decouples storage from any specific query engine. The same dataset stored in S3 can be directly queried using various platforms like Snowflake, BigQuery, Databricks, DuckDB, etc, leading to commoditisation of data warehouse resources.
Parquet storage format is specifically optimised for direct querying. In our projects, using Parquet seemed ideal because of its support for semi-structured data via the 'struct' column type. However, one challenging aspect of the Parquet format is that struct columns require standardised schema. I believe this is due to how Parquet organises data internally, which enables efficient querying of nested data.
Given that in our case schemas can vary by project and even by row, working with struct type becomes very non-trivial when processing larger amounts of data. In order to infer schema from the data we either have to load all of it into memory which is not always practically possible or come up with some solution that would process the data in chunks and then unify shema across those chunks. Cases when websites return data with slighly different structure are fairly uncommon, but they exist.
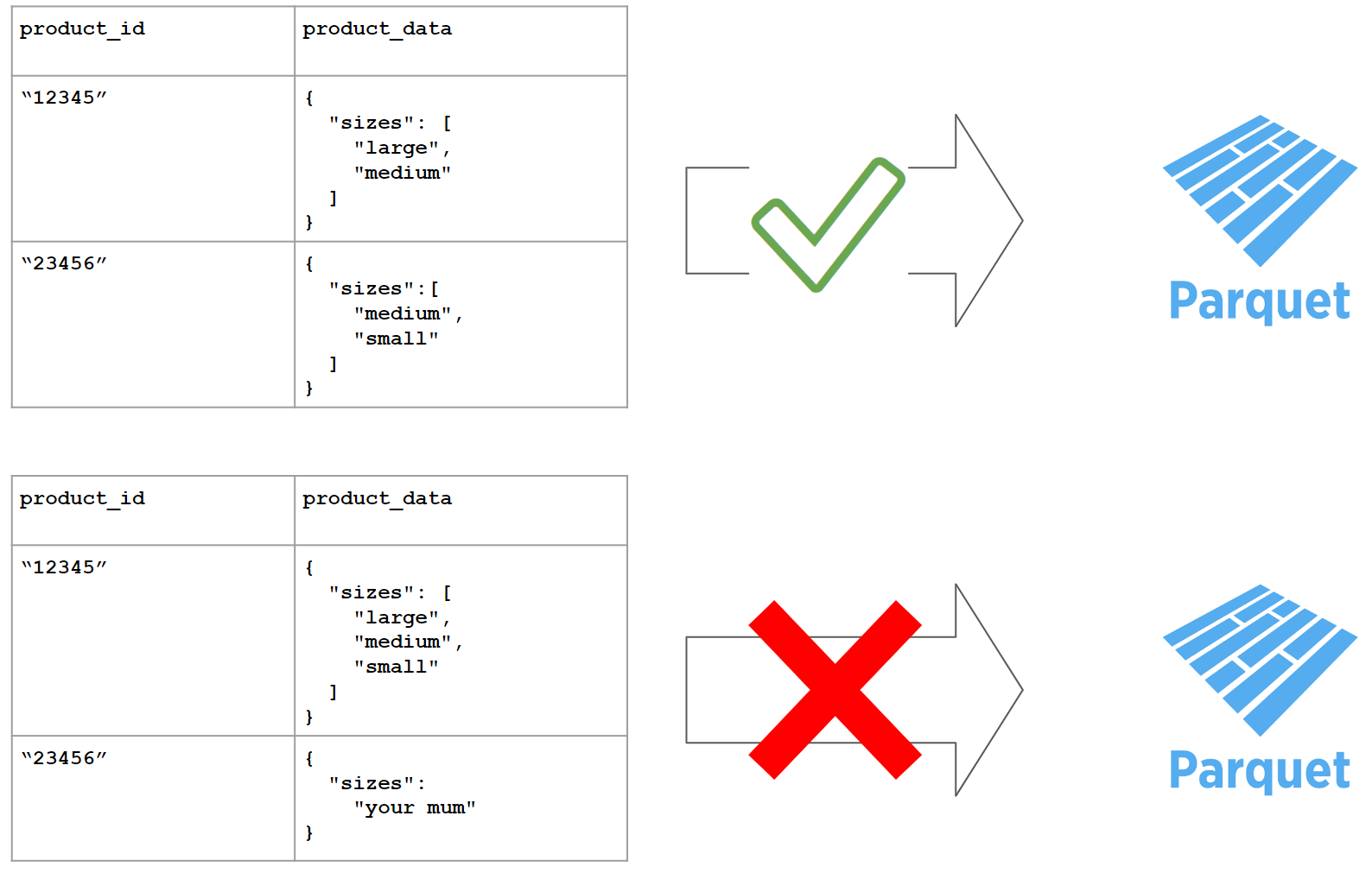
In the end, we settled on using two different formats based on the specific needs of our projects, which, while not ideal, is the most pragmatic solution:
For 70% of our projects, we use brotli-compressed Parquet files, where nested data is stored in a struct column. This format is highly effective when dealing with consistent, well-defined schemas.
For the remaining 30%, we opt for bz2-compressed CSV files. This choice works best for projects with inconsistent schemas or larger data sizes, offering better memory efficiency and complete schema flexibility at the expense of more complex data processing requirements down the line.
The Small File Problem
Storage format plays a big impact on the data ingestion performance. Recently, I encountered unexpected delays when ingesting data for one of the projects. After starting the usual COPY INTO command in Snowflake, I found myself staring at the screen for two hours before the job completed, wondering how much this single ingestion task is going to add to our next monthly Snowflake bill.
I reached out to my good friend Christian Silva, who happens to be one of the most knowledgeable people on the subject of cloud data architectures, and here's what he had to say:

Snowflake support confirmed Christian’s suspicion, and as stated in Snowflake’s documentation:
To optimize the number of parallel operations for a load, we recommend aiming to produce data files roughly 100-250 MB (or larger) in size compressed
The data that we work with is sometimes collected on an hourly basis, producing small files, sometimes as little as 100-200KB in size when compressed. Generating larger files from such fragmented data requires significant post-process merging.
To better understand the impact of file size on ingestion performance, I picked a project where we are collecting data for a number of countries and did an experiment, ingesting data from S3, comparing a number of different storage methods:
Hourly data, split into ~35 separate csv files, one file per country, compressed with gzip. This is basically how we are collecting and storing data for this specific project today.
Consolidated hourly csv files, compressed with bzip2.
Consolidated hourly brotli-compressed parquet files, storing JSON data as strings (this requires JSON parsing after the load).
Consolidated hourly brotli-compressed parquet files, storing JSON data as a parsed “struct” column.
Below are the the results:
Some comments on the results:
Consolidating files improves data ingestion times. “Small file problem” is a real issue, but it was not the only problem.
I was surprised to see Parquet loading to be faster than csv. To the best of my knowldge, csv generally outperforms Parquet for raw data ingestion, at least in Snowflake. Maybe this can be explained by different compression types: Brotli is a much more modern and more performant compression codec, compared to bzip2.
JSON parsing is a big contributor to the slow ingestion speed. Using struct column type in Parquet solves this problem - the data is delivered in a parsed format, making it a no-brainer for data ingestion and potentially opening up possibilities for querying data directly. Unfortunatelly it does not always work because of the strict schema requirement explained above.
Quick tip: AWS can be configured to generate daily reports with s3 inventory data. Under the bucket management settings we set up daily inventory reports and AWS automatically generates csv files with a list of all files in an s3 bucket, including some additional useful columns like file sizes and so on. With hundreds of thousands of files in our S3 bucket, making sense of the data became increasingly complex and these S3 inventory reports were very helpful in identifying and addressing some of the issues.
Summary
Getting data architecture right is a continuous process; it's not something that can be perfected on day one, nor is it ever truly complete. In this post, I've shared some of the key lessons I've learned so far, and I hope that readers will find them useful.
Nice post, thx Alex. Parquet is good. brotli also good in text compression but not too much tool could support it. Why you didn't use https://pola.rs (pip install polars) instead of pandas? also iceberg format could be good for storing clean tables.