
A Radical (And Expensive) Solution to Many Web Scraping Problems
The Ultimate Last Resort in Web Scraping

Web scraping is challenging. Continuous, consistent web scraping is even more so. There are numerous hurdles to overcome, including technical challenges like frequently changing site layouts and increasingly sophisticated bot-detection techniques, as well as legal considerations.
I've always been curious if there was a radical solution to these problems: manual scraping. As unconventional as it may seem, I've discovered that sometimes it's easier to hire people to manually collect data rather than investing a significant amount of developers' hours in building and maintaining an automated scraper. In an era where the focus is predominantly on AI-based scraping, I took the opposite approach and found that employing actual people to do the job can also be effective.
Of course, this approach won't work in all situations. If we need to collect data from thousands of pages frequently, then the cost becomes prohibitive. However, there are scenarios where we need to regularly scrape something very specific, sometimes from a particular web page, and this is where manual scraping proves to be effective.
How does it work?
As a personal project, I developed a web interface that integrates with a micro-tasking platform similar to AWS Mechanical Turk. Typically, these platforms are used to hire individuals for specific tasks such as labeling images for image recognition or completing surveys. Workers receive rewards for each task they complete, with each task usually taking no more than five minutes. So, I've listed my own “web data collection” task on one of these platforms. Through the platform, users access my interface, where they are provided with instructions on the data I need them to collect—whether it's a section of a webpage, a screenshot, or a bearer token that can be used for subsequent automated scraping. After submission, users are rewarded for completing the task, and all payments are handled by the micro-tasking platform.
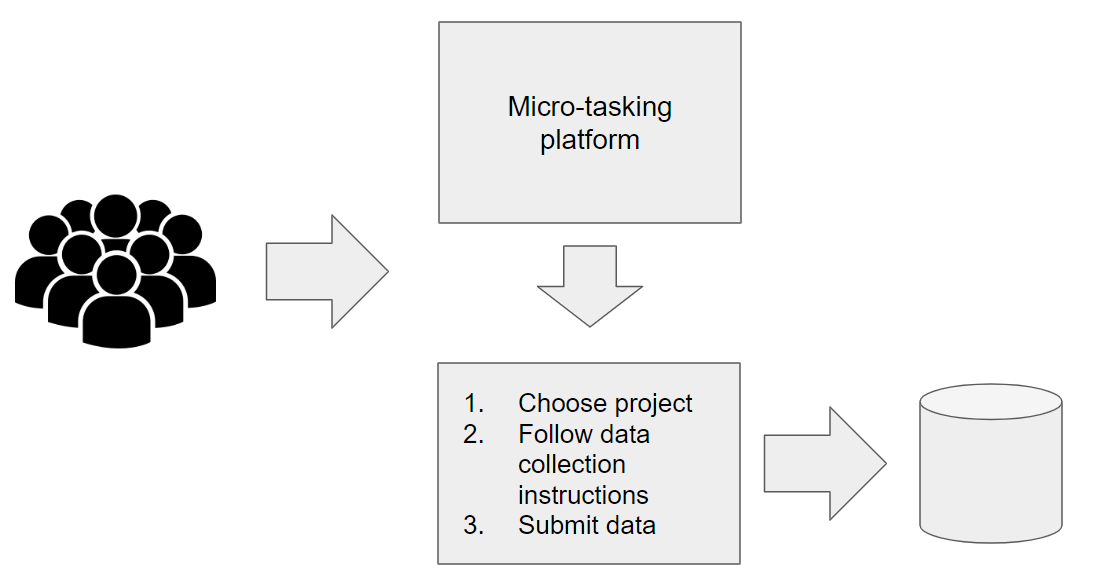
The UI and the logic that users interact with were built in Retool. Retool has become my newly discovered passion, and I find it to be an excellent tool for rapid software prototyping. Most people recognize Retool as a platform for developing internal corporate apps. Nowadays, Retool apps can also serve external users, which, in my opinion, enables many exciting new use-cases.
What are the advantages of this approach?
One significant advantage is compliance. With a real person conducting the data collection, there are fewer concerns about terms that prohibit automated access, such as those outlined in the robots.txt file. However, I must ensure that individuals do not violate any standard website terms and conditions, so normal compliance rules still apply (e.g., we can’t ask people to ignore “click wrap” terms of service or misrepresent themseves).
Another advantage is the ability to assign workers relatively complex scenarios that would be challenging to automate with traditional scraping methods. For instance, I can direct workers to search for and check the availability of a specific product or navigate through a complex checkout process.
Additionally, this method generally allows me to bypass issues related to changing website layouts, anti-ban protections, and similar obstacles, as long as a real person with average technical skills can navigate the scenario.
A practical example
Let’s consider a practical example of the data we can gather using this method, with Abercrombie and Fitch (NYSE: ANF) as our case study. As we navigate the checkout process on the abercrombie.com website and add items to a shopping cart, the website generates a data point that can be converted into the volume of shopping carts generated over time, potentially offering insights into user activity levels.
In theory, this data could be collected using traditional scraping methods, but there would be several obstacles. First, upon inspecting abercrombie.com/robots.txt file, we would notice that a significant portion of the website is restricted from automated access:
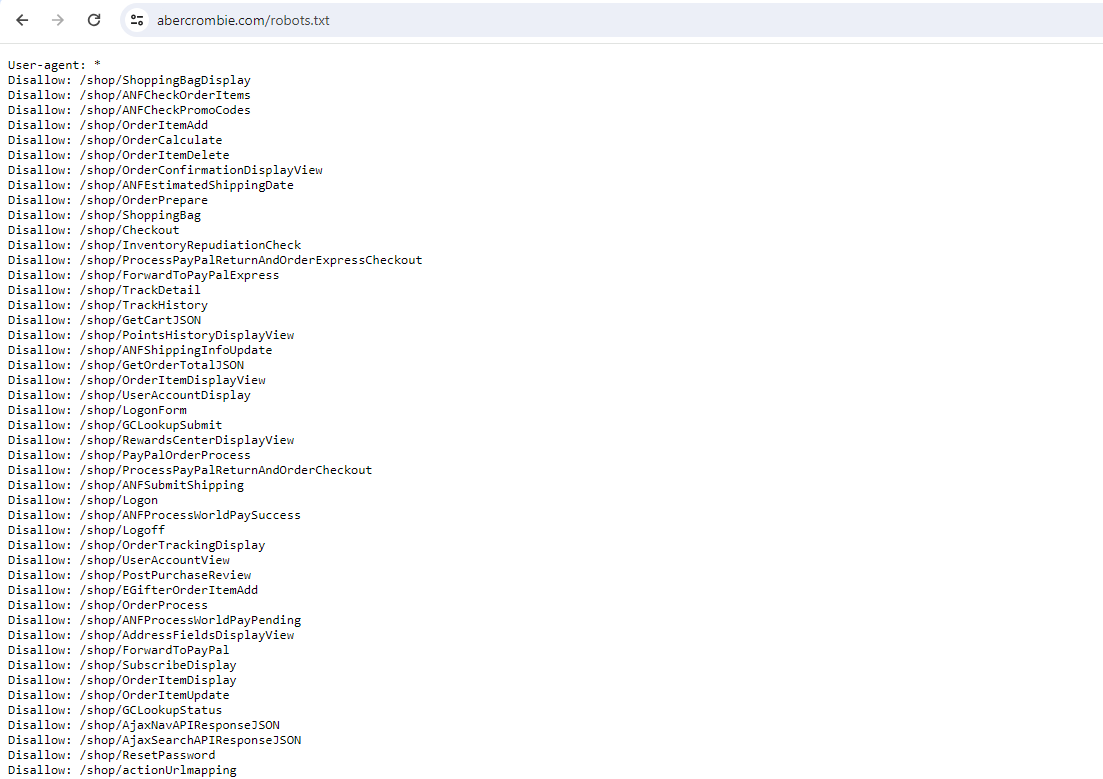
To the best of my knowledge, compliance with robots.txt is a gray area in web scraping; there are no specific laws that mandate adherence to its directives. However, some clients, particularly in the financial services sector, often have internal policies that prohibit accessing areas marked as disallowed by the robots.txt file. Strict internal compliance standards are common in the financial services industry. For example, I have encountered companies that were completely prohibited from using any residential proxy services—a practice otherwise common in the web scraping industry—due to compliance constraints. These rules make automated scraping very difficult and sometimes nearly impossible.
Additionally, the process of adding items to the shopping cart on the abercrombie.com website involves complex JavaScript operations that I found challenging to automate using traditional web scraping tools like Playwright.
Manual scraping resolves these issues — there is no "robot" involved in collecting the data, so we can be less concerned with the robots.txt file. Furthermore, since the interaction with the website is managed by a real person using a real browser, we don’t need to worry about automating complex JavaScript interactions.
Some considerations
Working with people introduces several new challenges:
Cost — Without sharing specific numbers, it's evident that "human" scraping is significantly more expensive and less efficient compared to traditional scraping. I use it as a last resort and only when the amount of data that needs to be collected is very small.
I had to find an easy way to scale the system across many projects and to easily add data collection instructions for each new project. This was achieved by embedding Google Docs into Retool. I also needed a method to monitor data collection at scale, something I might expand upon in the future.
Data quality — When real people submit data, there is always the potential for human error, whether intentional or unintentional. People might submit stale data or try to submit duplicate data, etc. So I had to think how to make the process more “human-error proof“ and even developed a basic worker reputation system. While many people participate in the data collection process, only a small fraction of workers, known for submitting high-quality data, complete the majority of the work.
I had to find a way to control the frequency of data collection.
I had to ensure that I was not collecting any personally identifiable information. All interactions with workers are completely anonymized.
After resolving these issues, I now have a system that has been operational for a few months. Maintenance has proven to be significantly easier compared to a conventional web scraping operation.
Some basic stats from the system's usage over the last five months:
Data is being collected from 57 websites.
21,218 web data collection tasks have been completed and submitted by users.
426 users submitted at least one task.
The top 10% of users submitted 97% of all tasks.
Approximate geographical location of users (exact locations are never known; this is only an approximation):
Bangladesh — 36%, India — 18%, Sri Lanka — 16%, other countries — 30%.

With many companies focusing on developing AI-based web scraping tools, I am hopeful that one day we will have a system intelligent enough to read and follow the same instructions that I currently provide to users. When that day arrives, the two methods will converge, opening new possibilities for performing complex web data collection at scale.
Great piece, it's important to keep considering the cost (and flexibility) of the human tasks also in this field, which for specific cases (low volume, hard difficulty, low refresh frequency) is often a solution. Personally, I think there are so many techniques that are good in specific cases, and no solution has proved bulletproof in all circumstances. I believe that keeping in mind the "human" alternative is a must.